Feature Extraction in Traditional ML vs Deep Learning
What is Feature Extraction
Machine learning models do not understand the world the way humans do. They do not see images, read words, or feel patterns intuitively. Instead, models understand numbers. Every input to a model—whether it is a medical record, an image, a sentence, or an audio clip—must ultimately be represented numerically.Feature extraction is the process that makes this possible. In simple terms, Feature extraction is the art of converting real-world information into meaningful numerical representations that models can learn from.

Why Feature Extraction Matters:
- Raw data is not directly useful
- Models need clean, meaningful inputs
- Better features → better performance
Without proper features:
- Raw data remains noisy and unstructured
- Models struggle to learn useful patterns
- Performance degrades, even with powerful algorithms
This is why feature extraction often determines whether a model succeeds or fails.
Feature Extraction in Tabular Data
Tabular data is often the most intuitive place to start because the structure is already defined.
Consider a healthcare dataset containing:
- Height
- Weight
- Blood Pressure
- Heart Disease (Yes/No)
Instead of feeding raw height and weight directly, we might engineer a more meaningful feature such as BMI:

Similarly:
- Blood pressure values may be normalized
- Age may be scaled
- Categorical fields (e.g., gender, symptoms) may be encoded numerically This transformation results in features that better align with the prediction task, such as estimating heart disease risk.
Common Feature Extraction Techniques in Traditional Machine Learning
Some of the most widely used feature extraction techniques include:
Feature Encoding
- Categorical → One-hot encoding
- Symptoms → keywords or embeddings
- Normalization of numerical values
Dimensionality Reduction
- PCA (Principal Component Analysis)
Used for dimensionality reduction, simplifying complex, high-dimensional data into fewer, more manageable principal components while retaining most of the important information
- SVD (Singular Value Decomposition)
Matrix factorization technique that breaks down any matrix into meaningful parts, revealing its underlying structure by identifying dominant features, reducing noise, and creating low-dimensional approximation
A key characteristic of traditional machine learning is that:
- Feature extraction is manual and domain-driven.
- The quality of features depends heavily on human expertise.
Domain-Specific Feature Engineering
Feature extraction is deeply tied to the domain.
Healthcare
- BMI
- Aggregated lab results
- Risk scores derived from multiple measurements
Biochemistry / Bioinformatics
- Amino acid sequence encodings
- Molecular fingerprints
- Gene expression vectors
Each domain requires specialized knowledge to determine what information matters and how it should be represented numerically.
What Makes a “Good Feature”?
A “good feature” is not universal—it depends on what task you want the model to perform.
Examples by Domain
Images
- Face recognition
- Emotion detection
- Age estimation
- Medical image analysis
- Autonomous driving (pedestrians, vehicles, signs)
Text
- Sentiment analysis
- Topic classification
- Spam detection
- Search and retrieval Different tasks require different representations—even when using the same raw data.
Limitations of Manual Feature Engineering
Traditional feature extraction has several drawbacks:
- Requires domain experts
- Time-consuming to design and validate
- Hard to generalize across tasks
- Performs poorly on raw data such as images, audio, and text As data becomes more complex, manual feature engineering becomes a bottleneck.
How Deep Learning Changes Feature Extraction
Deep learning fundamentally shifts how features are created. Instead of humans defining features explicitly, deep neural networks learn features automatically from raw data.
In traditional machine learning:
- Humans design features
- Models only learn decision boundaries
In deep learning:
- Networks learn both features and classifiers together
- Representations become increasingly abstract across layers

This reduces the need for handcrafted features and enables models to work directly with raw inputs like pixels, waveforms, or tokens.

The model starts with random feature weights
-
During training, predictions are compared with true labels
-
Errors are propagated backward through the network
-
Feature weights are updated to reduce prediction error
-
Over time, meaningful features are learned automatically
In short: Feature weights are learned through backpropagation during model training.
Handwritten Digit Recognition
Consider handwritten digit recognition using a fully connected neural network.

How an Image Is Represented
- An image is a grid of pixels
- Each pixel stores a numerical value
- The grid has height × width dimensions

- In Gray-scale image, each pixel has one value representing intensity (dark → bright). 0 → black and 255 → white
- In Color image, each pixel has three values for Red, Green, Blue and Represented as three stacked grids
For simplicity we are working with gray-scale images here. Let's say we feed the image into deep learning model as shown below.
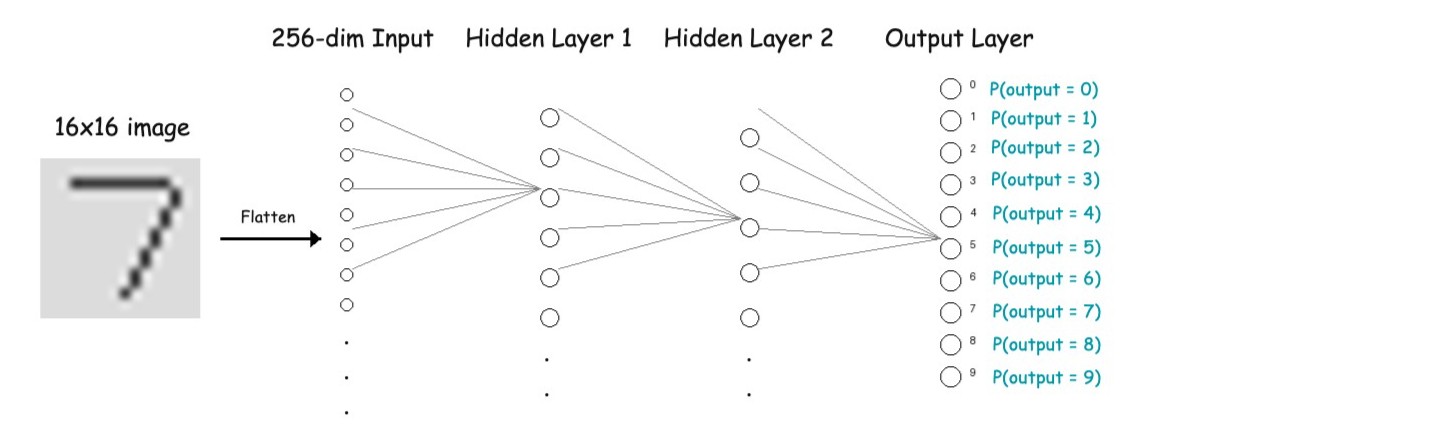
Input Layer
- A 16×16 grayscale image
- Each pixel is a number
- Flattened into a 256-dimensional vector
Hidden Layers: Learning Hierarchical Features
This is just our assumptions on what these hidden layers are learning through model training.
Layer 1
- Learns simple stroke patterns
- Lines, edges, curves
- Local pixel combinations
Layer 2
- Learns digit-specific structures
- Loops, intersections, endpoints
Output Layer
- Produces probabilities for digits 0–9
Even without convolution, the network still performs feature extraction, but with limitations. We will discuss about convolution in "Feature Extraction for Computer Vision" lesson in details.
Limitations of Fully Connected Feature Learning
This approach has clear weaknesses:
- Ignores spatial structure
- Sensitive to small shifts or rotations
- Requires many parameters
- Does not scale to complex images
These limitations motivate convolutional neural networks (CNNs), which preserve spatial relationships.
Feature Extraction in Natural Language Processing (NLP)
Unlike images, text has:
- No pixels
- No natural spatial structure
- Variable length
Feature detection in NLP focuses on extracting patterns from language. The goal of feature extraction in NLP is to identify meaningful patterns in text — such as words, phrases, syntax, or context, encode relationships between words and converting them into numerical representations that models can understand. This makes NLP feature extraction uniquely challenging.
Traditional vs Deep Learning Features in NLP
Traditional NLP Features (Mostly word counts/frequency based approaches)
- One-hot encoding
- Bag of Words (BoW)
- TF-IDF
Deep Learning NLP Features
- Word2Vec→ Captures semantic similarity
- BERT and transformer-based models→ Captures contextual meaning
Deep learning embeddings move beyond counting words and instead represent meaning in vector space.
Feature Extraction for Audio Data
Audio is a time-varying signal. To analyze it, we extract features that summarize how the sound behaves over time and frequency.
Audio Features
Speech
-
Pitch: Fundamental frequency of voice, indicates tone and emotion
-
Formants: Vocal tract resonances, capture vowel and phoneme information
-
Speaking rate: Speed of speech, reflects fluency and cognitive state
Music
-
Tempo: Speed of music in beats per minute
-
Chroma features: Distribution of musical notes, capture harmony
-
Rhythm patterns: Repeating timing structures, represent beat and groove
Medical Audio
-
Heart sound intervals: Time gaps between heartbeats, indicate cardiac health
-
Lung crackle frequency: Short abnormal sounds, signal respiratory issues
Traditional Feature Extraction for Audio Data
-
Handcrafted features like MFCCs, pitch, tempo are manually designed
-
Domain knowledge is required to choose useful features
-
Features are fixed before training
Deep Learning–based Feature Extraction for Audio Data
-
Models learn features directly from raw audio or spectrograms
-
No manual feature design is needed
-
Features are learned automatically during training via backpropagation