Motivation: Why Neural Networks?
Artificial Neural Networks (ANNs) are inspired by the biological brain, which consists of billions of neurons connected through synapses. Each neuron receives signals, processes them, and passes the result forward.
Similarly, an artificial neural network is made up of artificial neurons that mimics a biological neuron or nerve cell:
- Receive inputs
- Perform weighted computations
- Produce outputs
The core motivation behind neural networks is simple:
We want machines to learn complex patterns directly from data, without explicitly programming rules.
Artificial Neuron vs Biological Neuron
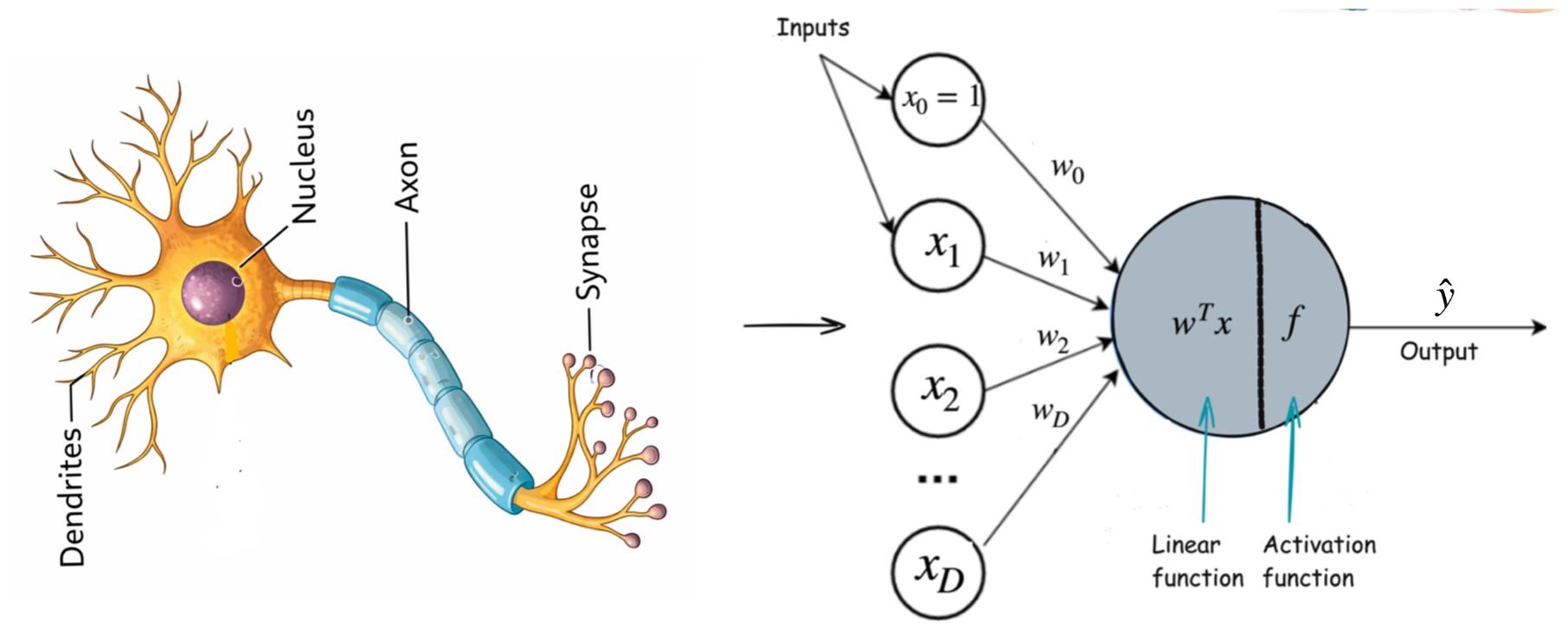
A biological neuron consists of:
- Dendrites → receive signals
- Cell body (nucleus) → processes signals
- Axon → transmits output via synapses
An artificial neuron mimics this behavior mathematically:
Where:
- s are inputs
- s are weights
- is the bias
- is an activation function
This abstraction allows us to stack neurons into layers, forming a neural network.
Why Traditional Machine Learning Is Not Enough
Traditional machine learning models such as:
- Linear Regression
- Logistic Regression
- Support Vector Machines
- Decision Trees
work well for simple, structured problems. However, they struggle in real-world scenarios.
Limitations of Traditional ML
- ❌ Poor performance on unstructured data
- Images
- Audio
- Text
- Video
- ❌ Does not scale well with large and complex datasets
- ❌ Fails when relationships are highly non-linear
As data complexity grows, traditional models start to fail.
This gap is exactly why neural networks are needed.
Why Do We Need Hidden Layers?
A network with only:
- an input layer
- an output layer
can only learn linear decision boundaries.
Hidden layers allow neural networks to:
- Learn non-linear patterns
- Build hierarchical feature representations
- Solve complex real-world problems
Most real-world problems are impossible to solve using only input and output layers.
Linear Separability and Logic Gates
This image illustrates how the logical functions AND, OR, NAND, and NOR can be represented in a two-dimensional input space and separated using a single linear decision boundary. Each plot shows the four possible input combinations (A,B), colored by their output class, with the dashed green line indicating the classifier’s decision boundary. Since a straight line is sufficient to separate the classes in all four cases, these functions are linearly separable and can be modeled using a single perceptron without any hidden layers.
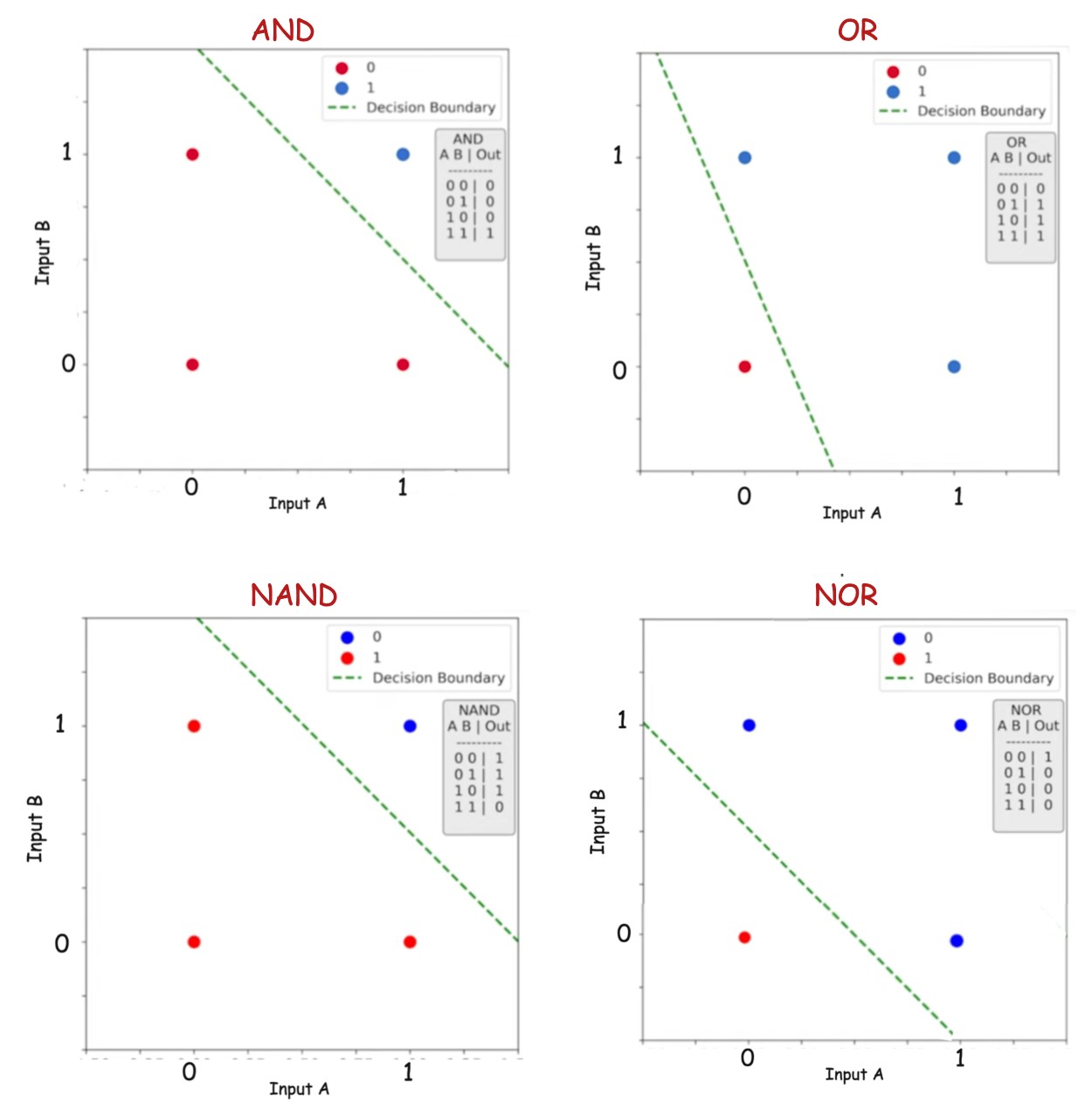
That means:
- A single straight line can separate the output classes
- A single neuron (perceptron) can model them
XOR: The Breaking Point
The XOR function outputs:
- 1 when inputs are different
- 0 when inputs are the same
XOR is not linearly separable.
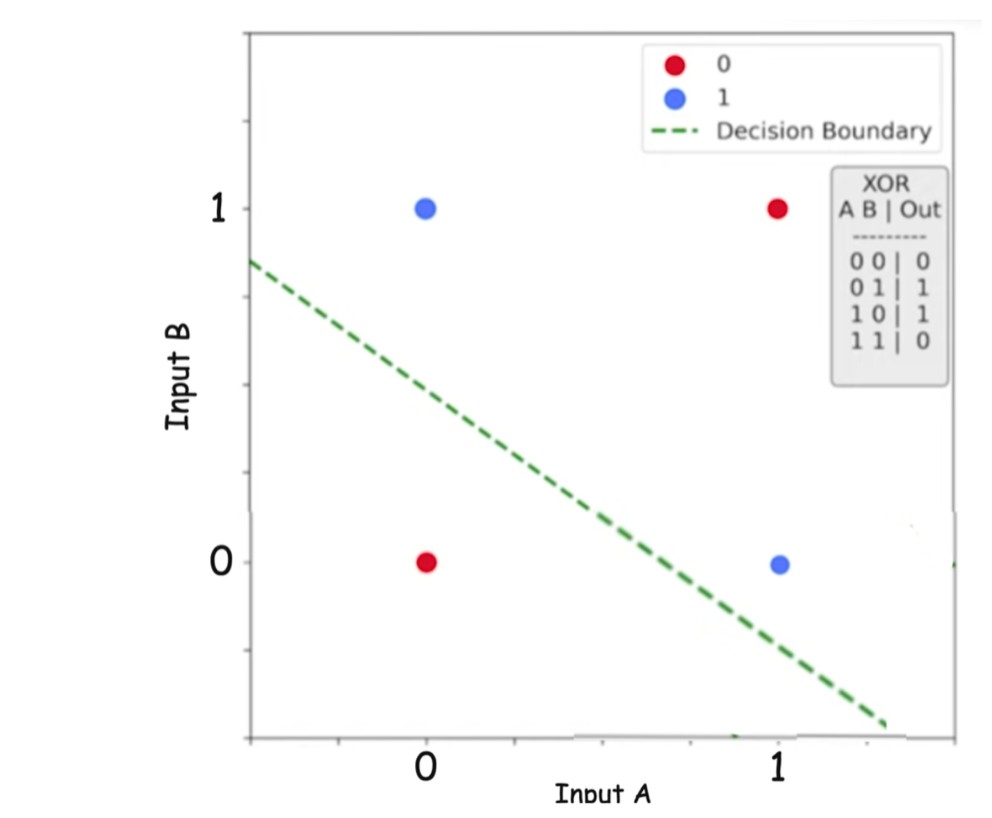
Unlike AND or OR, the positive and negative classes in XOR lie diagonally opposite to each other, making it impossible to separate them using a single straight decision boundary (shown by the dashed green line). This visualization highlights why XOR is not linearly separable and why solving it is not possible with just one neuron model.
This single example proves that single-layer models are insufficient.
Modeling AND and OR with a Single Neuron
AND Function Model
This diagram illustrates how the AND logical function can be implemented using a single artificial neuron (perceptron). The neuron receives two binary inputs, and , each scaled by their corresponding weights and . These weighted inputs are summed together along with a bias term , forming a linear combination This value is then passed through an activation function , typically a sigmoid or step function, to produce the final predicted output . We apply sigmoid here because we want to convert the neuron’s raw weighted sum into a bounded, interpretable output between 0 and 1.
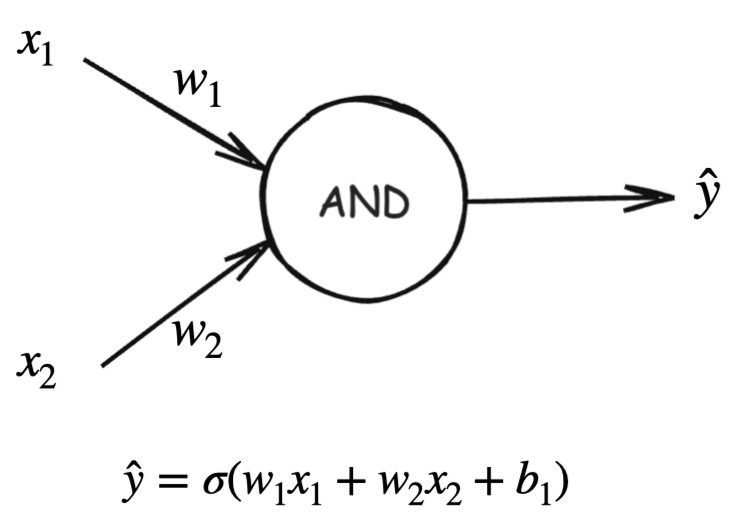
By choosing appropriate values for the weights and bias, the neuron activates (outputs 1) only when both inputs are 1, and remains inactive (outputs 0) for all other input combinations. This demonstrates that the AND function is linearly separable and can be perfectly modeled using a single perceptron without any hidden layers.
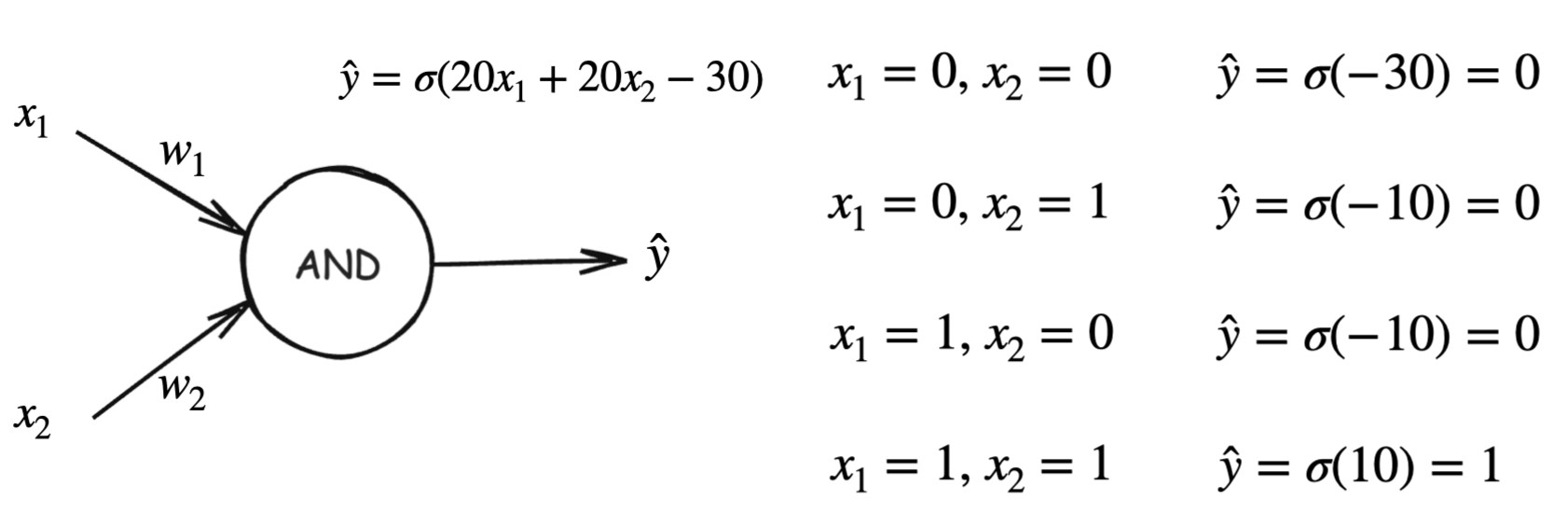
Output behavior:
- All other inputs →
OR Function Model
Similarly, by choosing appropriate values for the weights and bias, the neuron activates (outputs 1) when atleast one input is 1, and remains inactive (outputs 0) when both the inputs are 0.
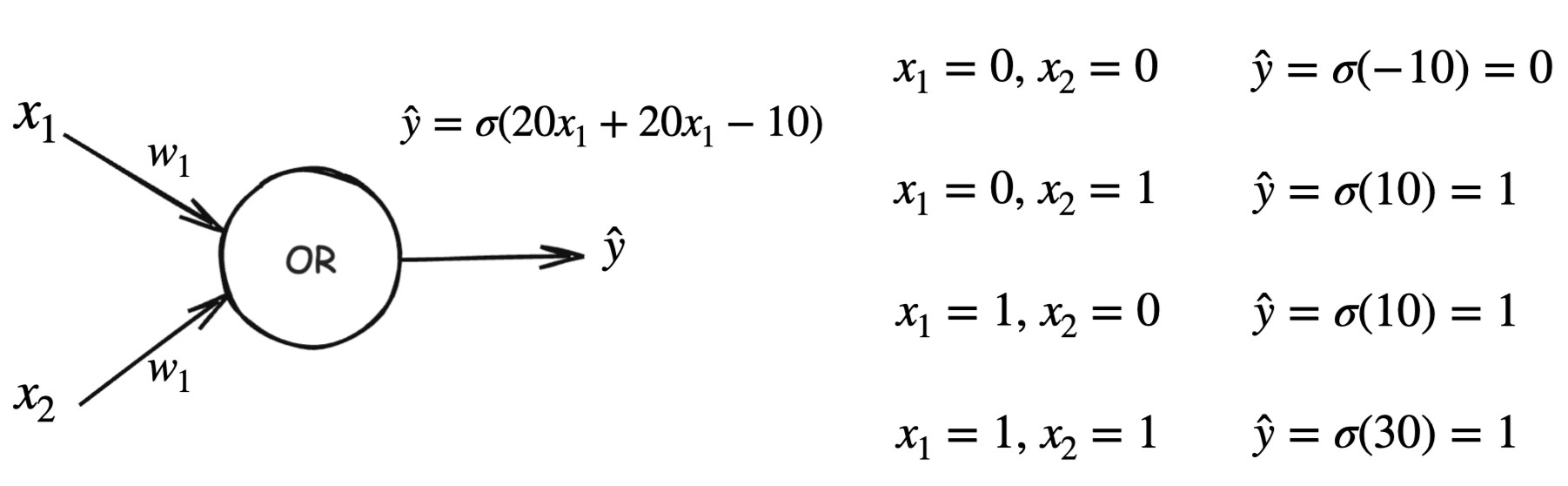
Output behavior:
- At least one input is 1 →
These examples show how:
- Weights control feature importance
- Bias shifts the decision boundary
- Sigmoid approximates binary outputs
Why XOR Cannot Be Solved with a Single Neuron
For a single neuron:
No choice of can correctly model XOR.
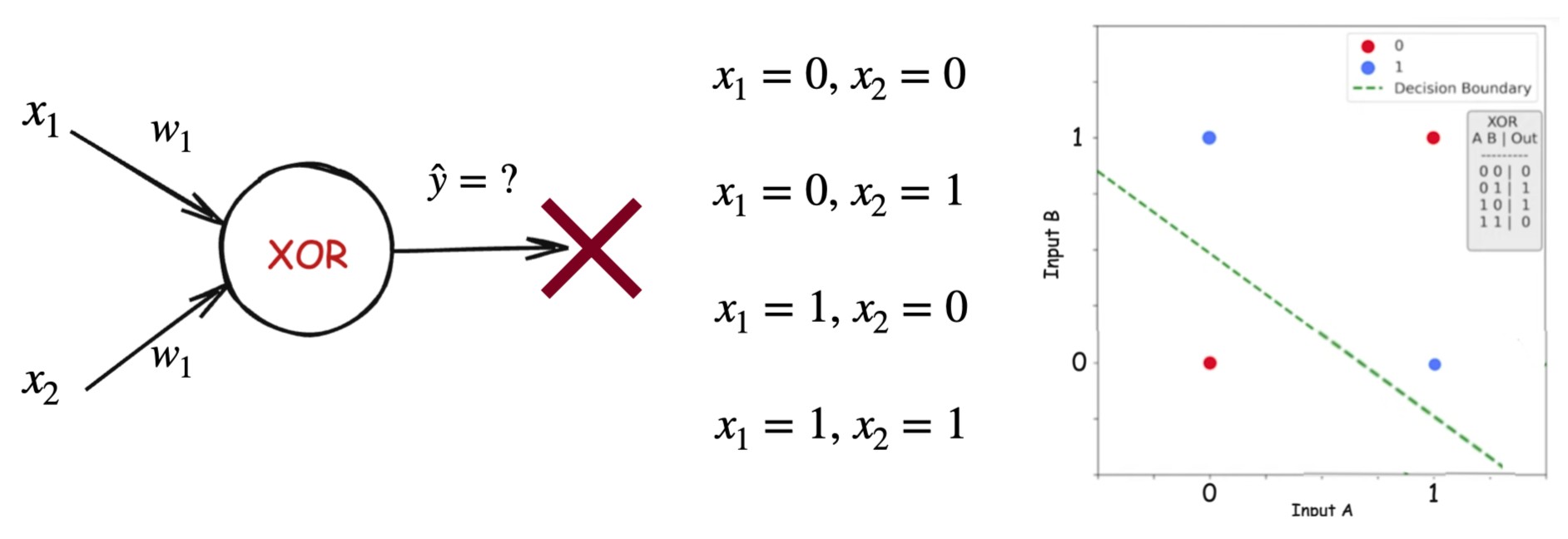
This is a fundamental limitation of single-layer perceptrons.
Decomposing XOR into Simpler Functions
XOR can be rewritten as:
Or equivalently:
This shows that XOR is:
- A composition of simpler logical functions
- Each of which is linearly separable
Solving XOR Using a Hidden Layer
To solve XOR, we add:
- One hidden layer
- Two hidden neurons
.jpg)
Hidden layer
Output layer
The four diagrams below illustrate how different input combinations activate the hidden neurons and lead to the correct output, demonstrating why hidden layers are necessary to solve non-linearly separable problems like XOR.
.jpg)
This network:
- Learns intermediate features
- Combines them to produce XOR
Depth solves the problem.
From Logic Gates to Deep Learning
Modern neural networks extend this same idea. A neural network is a layered computational model composed of interconnected neurons that transform inputs into outputs through weighted connections and nonlinear activation functions.
It contains:
- Input layer
- Multiple hidden layers
- Output layer
- Weights
- Activations
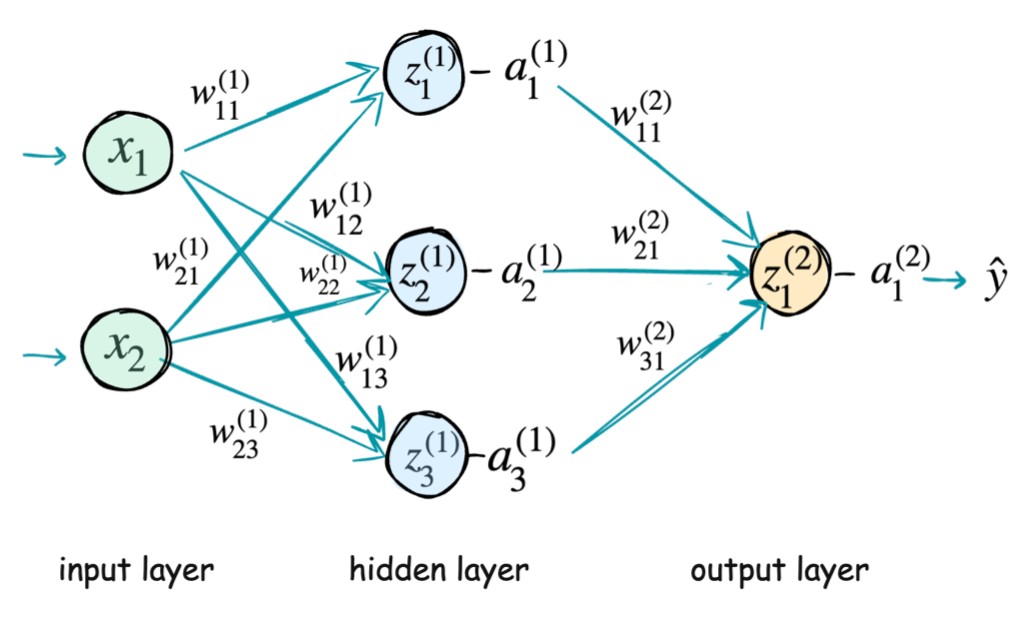
Input Layer
The input layer receives the raw features:
These values are passed forward without modification and serve as the starting point of computation.
Hidden Layers
Each hidden layer consists of neurons that perform two operations:
- A linear transformation
- A nonlinear activation
Here:
- is the weight connecting the -th neuron in layer to the -th neuron in layer
- is the bias of the -th neuron in layer
- is the activation from the previous layer
Hidden layers enable the network to learn hierarchical and non-linear representations of the input data.
Output Layer
The output layer applies the same computation to produce the final prediction:
Depending on the task, the activation function in this layer may vary (e.g., sigmoid for binary classification, softmax for multi-class classification).
Key Idea
By stacking multiple layers and learning the parameters and , neural networks can approximate complex functions and model intricate patterns in data that are difficult or impossible to capture with linear models.
Neural networks learn representations, not rules.
Why Depth Matters
Hidden layers allow neural networks to:
- Learn intermediate concepts
- Build reusable feature hierarchies
- Approximate complex non-linear functions
Examples:
- Vision: edges → shapes → objects
- Language: characters → words → meaning
- Audio: frequencies → phonemes → speech
Depth is not optional — it is the source of intelligence.