Activation Layer - Motivation
Activation layers play a critical role in neural networks. Without them, even deep networks collapse into simple linear models and fail to learn complex patterns.
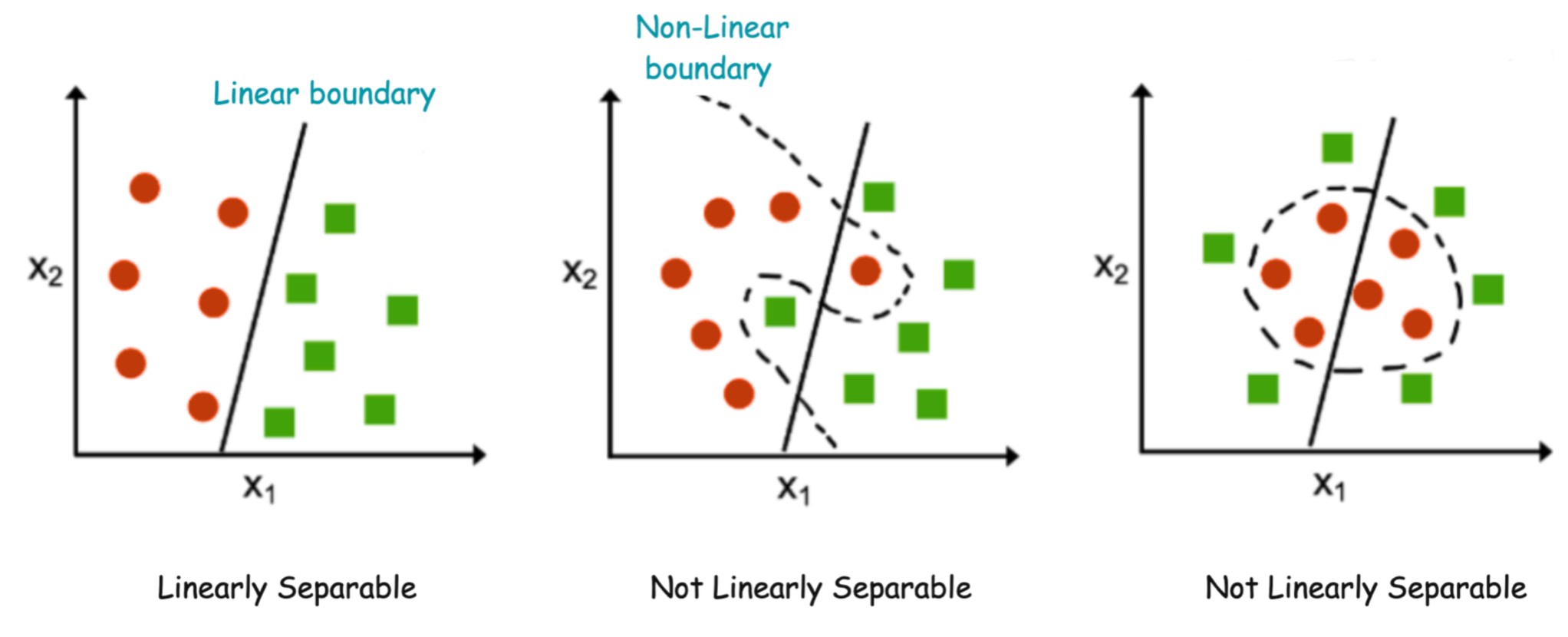
Why Do We Need Activation Layers?
Consider a neural network with a hidden layer but no activation function.
.jpg)
For a hidden layer:
And an output layer:
Substituting the hidden layer equations:
Here ,
This shows that without activation functions, the entire network reduces to a single linear equation, no matter how many layers it has.
Stacking linear layers still results in a linear model.
Why Linear Models Fail: The XOR Problem
The XOR function is a classic example that exposes the limitation of linear models.
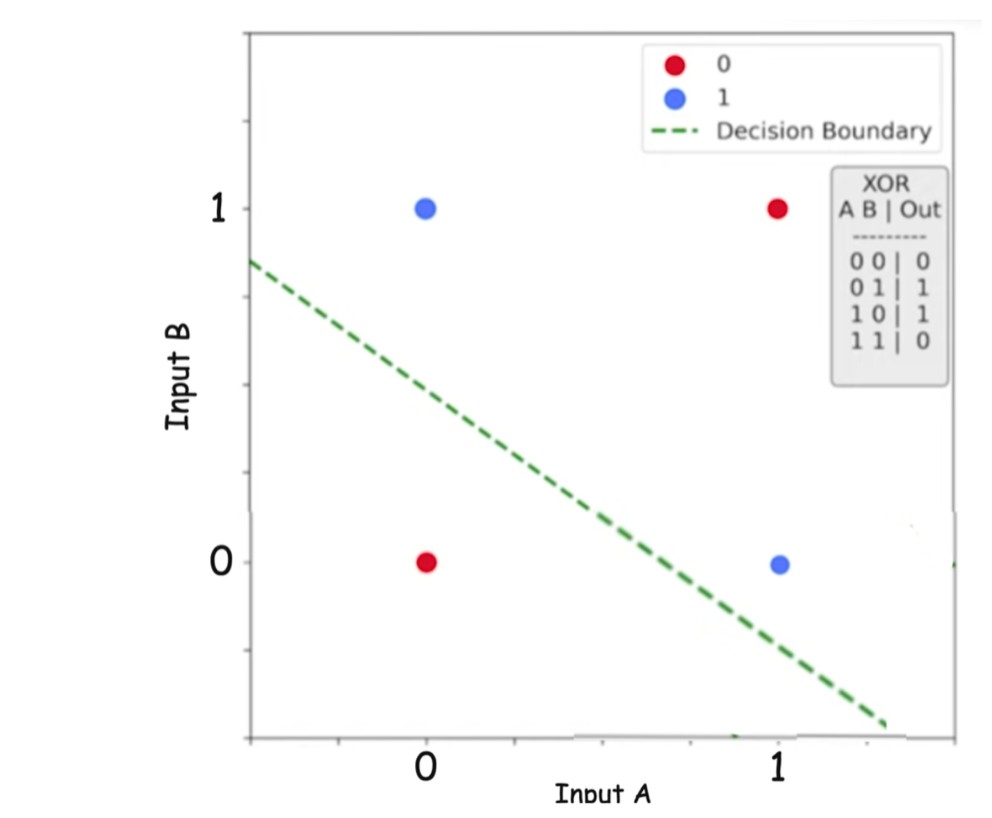
XOR is not linearly separable, meaning:
- No single straight line can separate its classes
- Any model of the form will fail
This is why non-linearity is essential.
Activation Functions Introduce Non-Linearity for Real Word Data
Most real world data are non-linear, and without activation layer we won't be able to represent them.
-
Image Classification: Recognizing a cat in an image requires understanding curves, textures, shapes, and spatial relationships — all inherently non-linear patterns.
-
Natural Language Processing (NLP): Understanding and classifying human language (e.g., sentiment analysis, spam detection, translation) involves non-linear relationships between words and context.
-
Recommender Systems: Predicting user preferences for products, movies, or music involves highly non-linear interactions between user history, item features, and context.
-
Speech Recognition: Audio data contains complex patterns that vary greatly, requiring non-linear models to interpret human speech accurately.
-
Autonomous Driving: Data used for object detection and decision making in self-driving cars (e.g., distinguishing pedestrians from vehicles in real-time video feeds) is inherently non-linear.
Activation functions:
- Break linearity
- Allow neural networks to learn complex decision boundaries
- Enable hierarchical feature learning
Linear models cannot capture these relationships
Sigmoid Activation Function
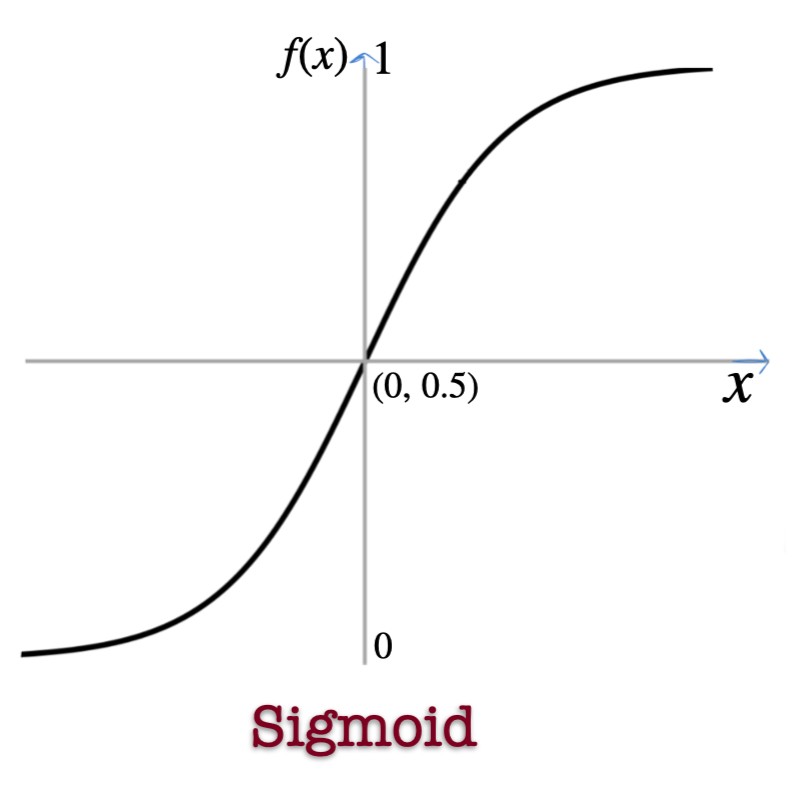
Properties
- Output range:
- Smooth and differentiable
Where It Is Used
- Output layer for binary classification
- When probabilities are required
Why It Works
- Outputs can be interpreted as probabilities
- Enables gradient-based learning
Limitations
- Vanishing gradient problem
- Not zero-centered
- Slow training in deep networks
Hyperbolic Tangent (tanh)
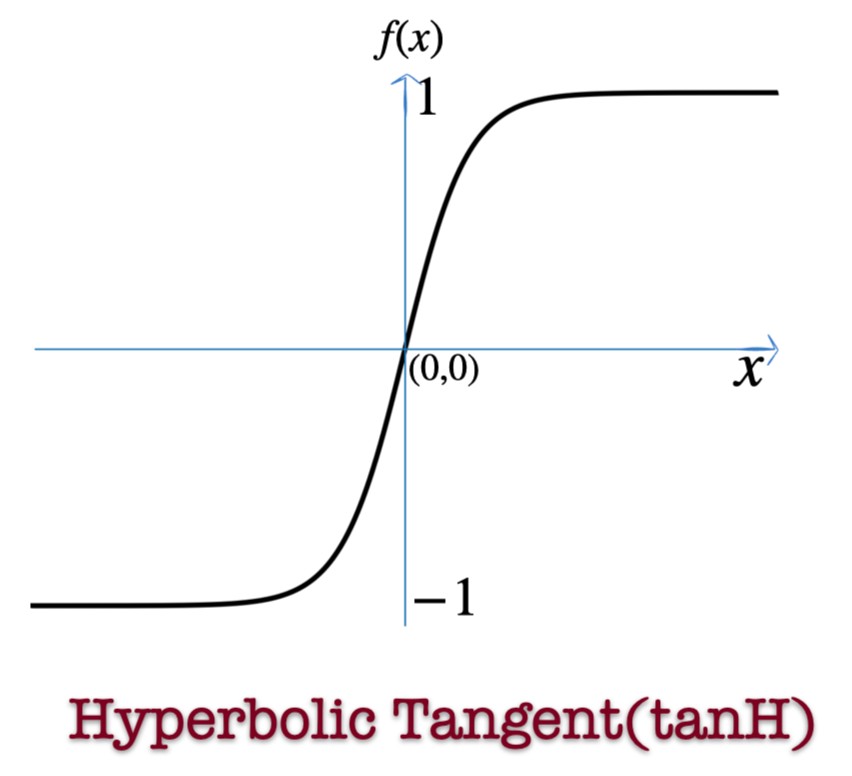
Properties
- Output range:
- Zero-centered
Where It Is Used
- Hidden layers in older networks
- RNNs and LSTMs
Why It Works
- Stronger gradients than sigmoid
- Better convergence than sigmoid
Limitations
- Still suffers from vanishing gradients
- Slower than ReLU
Rectified Linear Unit (ReLU)
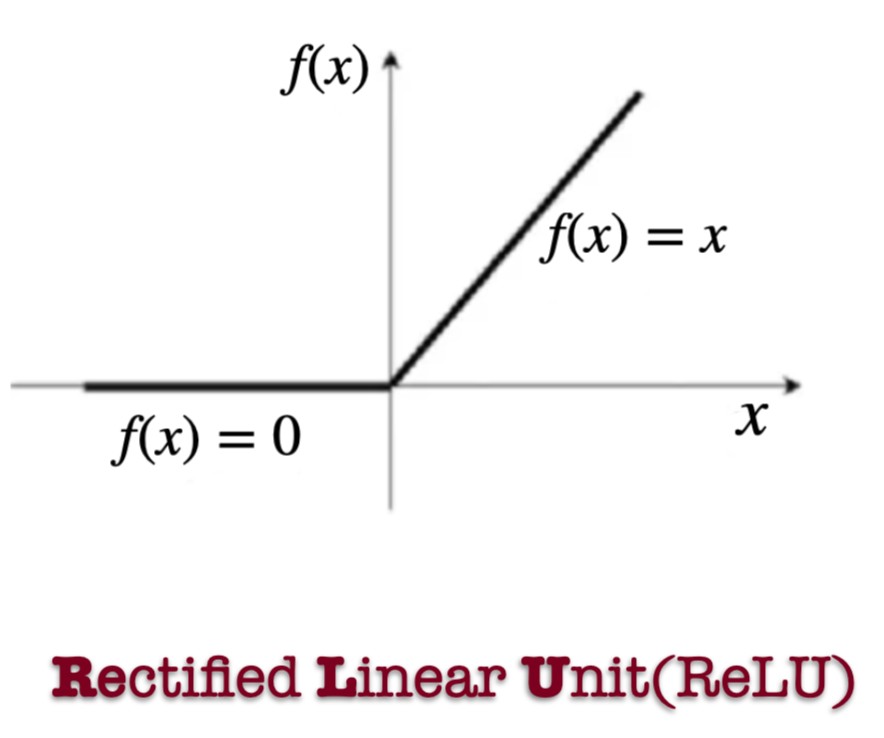
Where It Is Used
- Hidden layers of deep neural networks
- Computer vision models
- Most modern deep learning architectures
Why It Works
- Fast computation
- No vanishing gradient for
- Sparse activation helps reduce overfitting
Limitations
- Dying ReLU problem (neurons stuck at zero)
Leaky ReLU
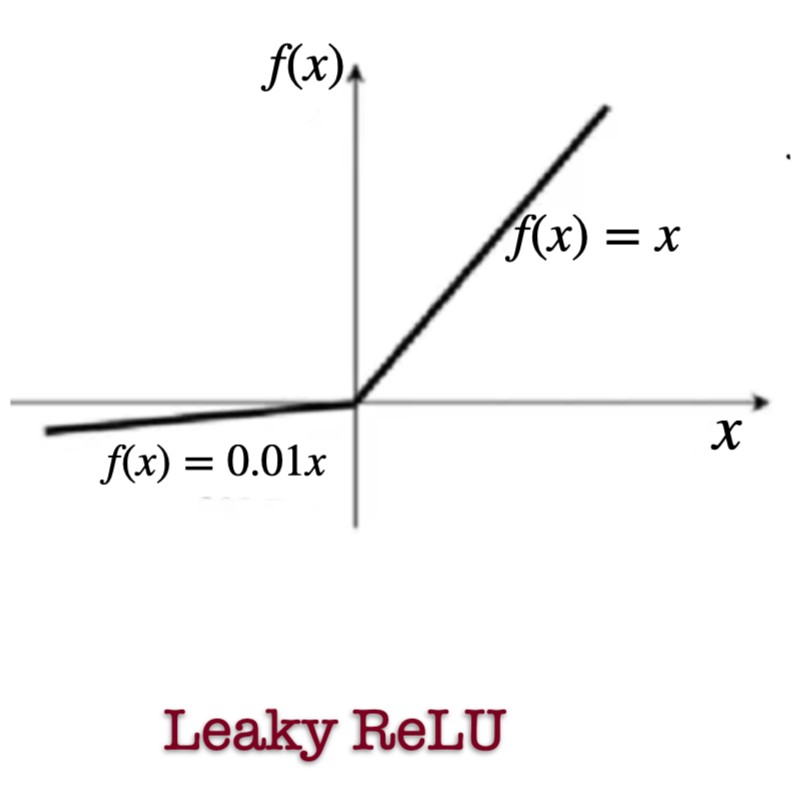
where .
Where It Is Used
- Hidden layers when ReLU fails
- GANs
- Deep CNNs with dying ReLU issues
Why It Works
- Prevents neurons from dying
- Maintains small gradients for negative inputs
Limitations
- Slightly slower than ReLU
- is a hyperparameter
Softmax Activation Function
If there are classes :
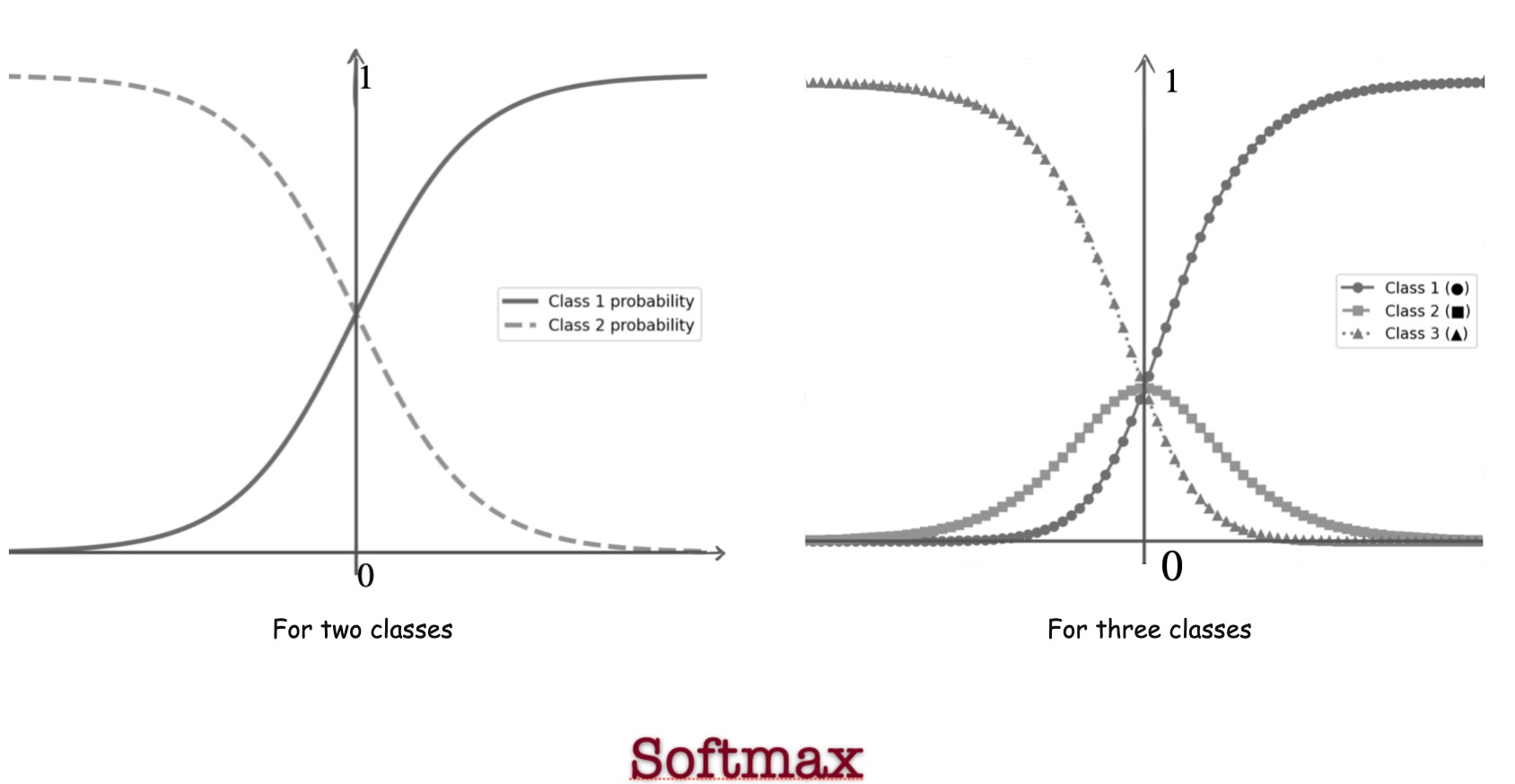
Where It Is Used
- Output layer for multi-class classification
- Final layers of CNNs
- Transformer architectures
Why It Works
- Converts raw scores into probabilities
- Outputs sum to 1
- Differentiable and trainable
Limitations
- Only suitable for mutually exclusive classes
- Sensitive to large values (numerical overflow)
- Not used in hidden layers
- Vanishing gradients when one class dominates
Key Takeaways
- Without activation functions, neural networks collapse into linear models
- Non-linearity is essential to solve real-world problems
- Different activation functions serve different purposes
- Choosing the right activation function is crucial for performance
Activation functions are what give neural networks their power.